Title
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Time
2021.9
Publish
Emnlp2021
Summary

- 提出了目前在sentence embedding 领域表现最优的对比学习框架SimCSE
- 首先使用无监督方法,将输入sentence和其预测的sentence1作为对比目标,其只经过一个标准的dropout作为噪音,取得的很好效果,与以前的有监督效果相当。
- 其发现利用 dropout作为数据增强操作有很好的效果,且移除它会导致表示效果变差。
- 进而提出有监督方法。标注的自然语言推理数据集输入对比学习框架,使用“entailment”数据作为正样本,“contradiction”作为hard 负样本。
- 最后在STS任务评测,无监督、有监督simcse+bert_base 斯皮尔曼相关系数分别提升4.2%、2.2%
- 证明:对比学习 正则化了 预训练模型嵌入 各向异性空间变得更加统一,使用监督学习能够使得正样本更好的对齐。
Method(s)
无监督SimCSE实现
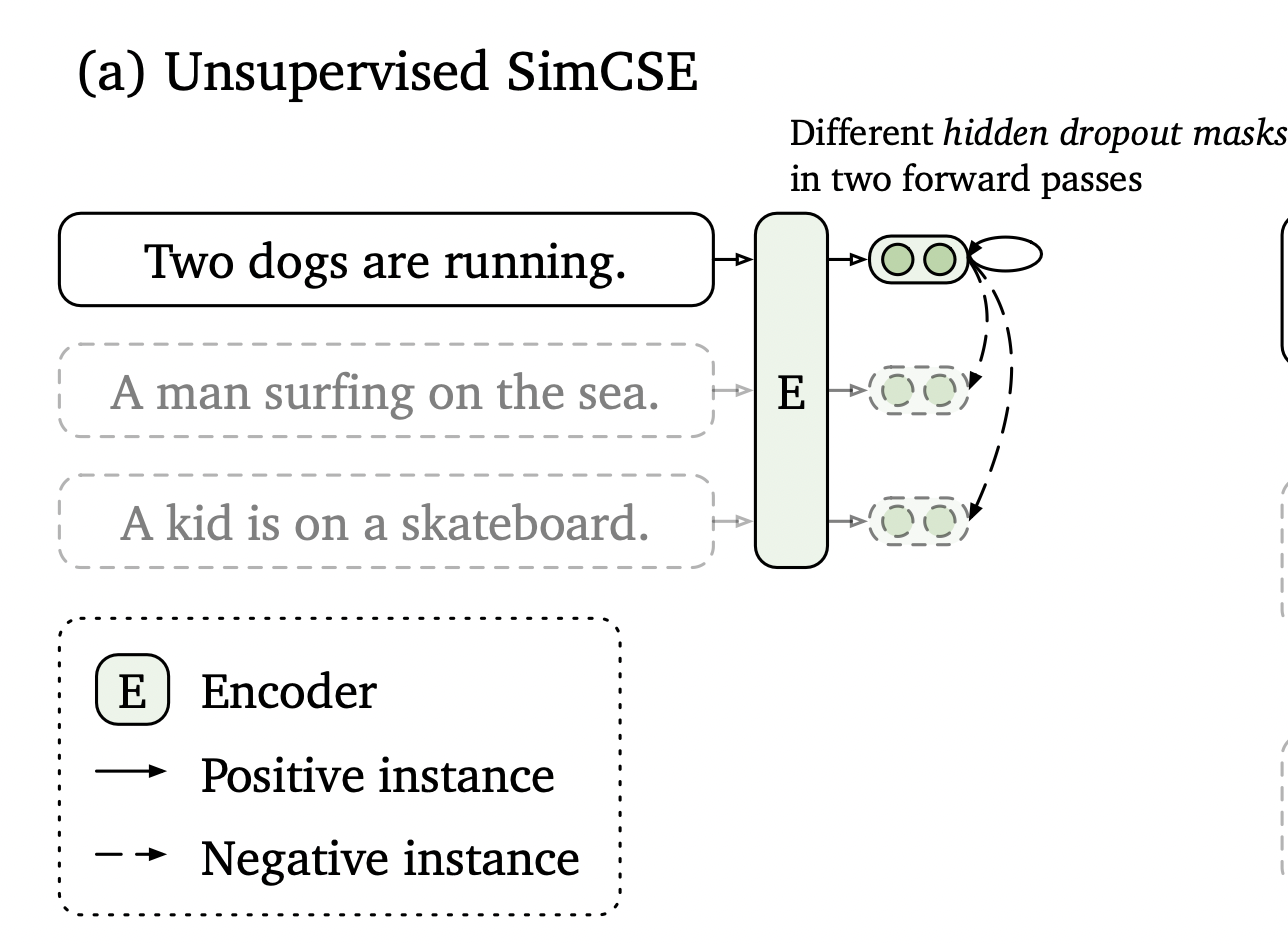
- 将句子输入 dropout作为noise
- 将同一句输入预训练模型编码器两次:应用标准的dropout两次。获得两个不同的嵌入作为“positive pairs”
- 同一个batch其他句子,组合作为“negatives”
- 最后模型从这些“negatives”中预测“positive”
train objective
同样的input到编码器两次,获得两个embedding\(z\),\(z^{\prime}\)
\(\ell_{i}=-\log \frac{e^{\operatorname{sim}\left(\mathbf{h}_{i}^{z_{i} }, \mathbf{h}_{i}^{z_{i}^{\prime} }\right) / \tau} }{\sum_{j=1}^{N} e^{\operatorname{sim}\left(\mathbf{h}_{i}^{z_{i} }, \mathbf{h}_{j}^{z_{j}^{\prime} }\right) / \tau} }\)
\(z\)仅仅使用transformer标准的dropout mask
结论:dropout对隐藏的表示起到了最小的“数据扩充”作用,而删除它则会导致表示崩溃。
有监督SimCSE实现
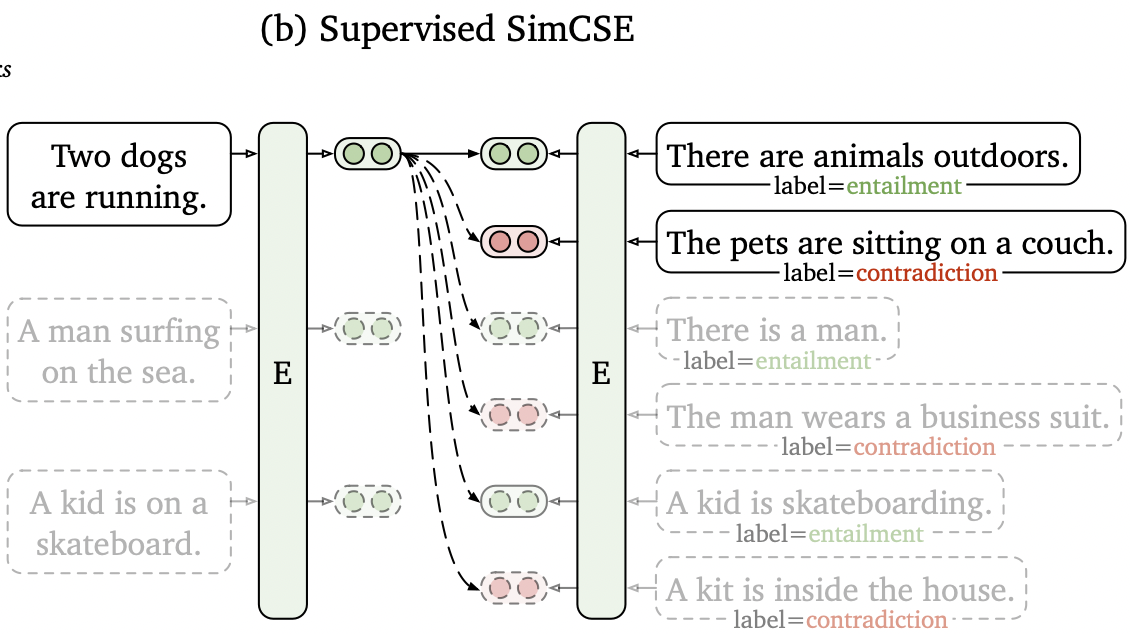
1.将原有三分类任务(蕴含,中立,相反)降低为(蕴含,相反),其中“中立”被视为正样本。
2.添加对应的相反 语句对视为 hard negative 进一步提升表现。NLI数据集效果尤其好。
train objective
将\(x,x_i^+\)扩展为\(x,x_i^+,x_i^-\),以\(x\)为基础,\(x_i^+\)和\(x_i^-\)为蕴含和相反 假设
其训练目标为
\(-\log \frac{e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right) / \tau} }{\sum_{j=1}^{N}\left(e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{j}^{+}\right) / \tau}+e^{\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{j}^{-}\right) / \tau}\right)}\)
Evaluation
对比学习分析工具:
alignment
测试语义相关的正样本对齐程度
\(\ell_{\text {align } } \triangleq \underset{\left(x, x^{+}\right) \sim p_{\text {pos } } }{\mathbb{E} }\left\|f(x)-f\left(x^{+}\right)\right\|^{2}\)
其中\(p_{pos}\)表示 语句对对应的分布式的句向量,假设其中表示均已正则化
uniformity
利用整个表示空间的均匀性来衡量学习嵌入的质量
\(\ell_{\text {uniform } } \triangleq \log \underset{x, y \stackrel{\mathbb{i} . i . d .}{\sim} p_{\text {data } } }{ } e^{-2\|f(x)-f(y)\|^{2} }\)
这两个指标与对比学习的目标是一致的:正面实例应该保持接近,而随机实例的嵌入应该分散在超球体上。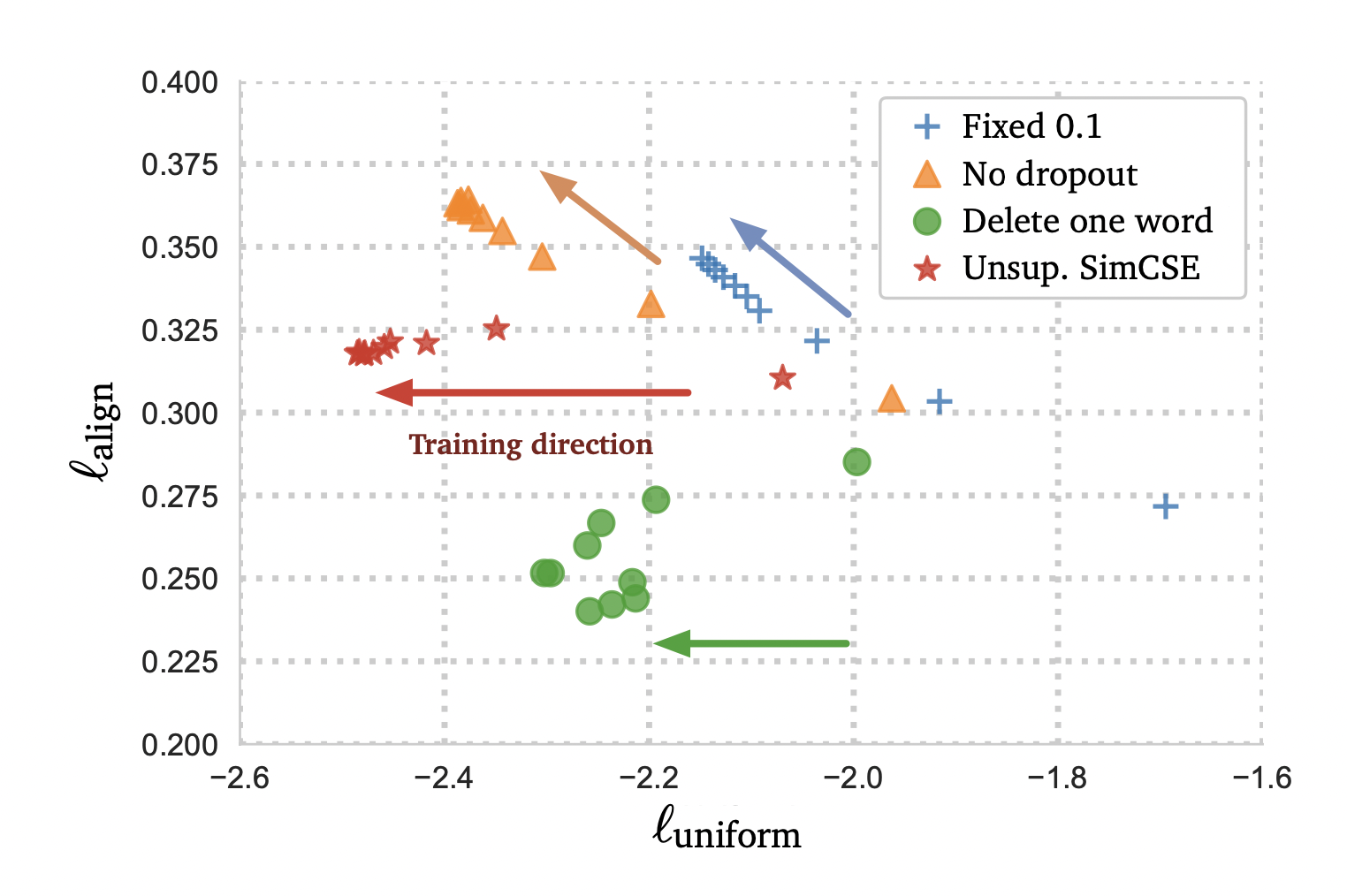

其数字越小越好
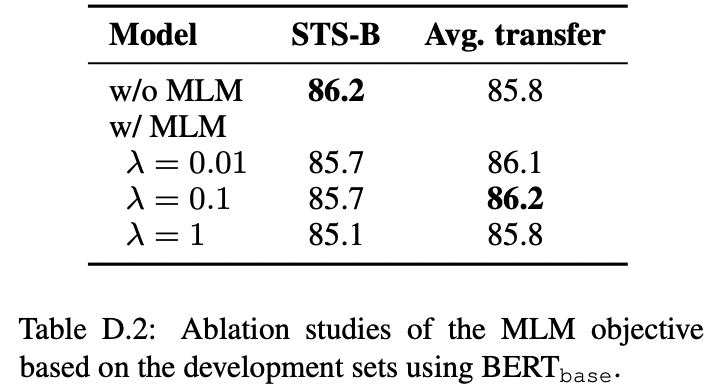
Conclusion
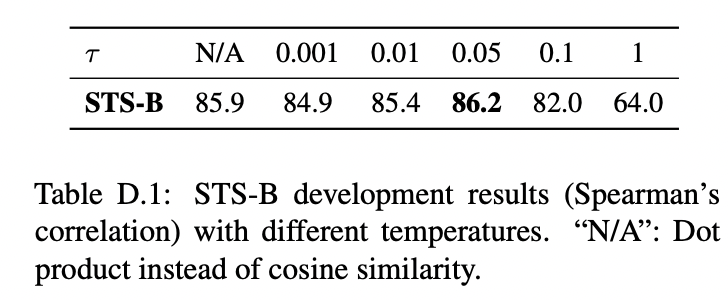
�
Notes
对比学习:
对比学习的目的是通过把语义上相近的邻居拉到一起,把非邻居推开来学习有效的表征
假定语句集\(\mathcal{D}=\left\{\left(x_{i}, x_{i}^{+}\right)\right\}_{i=1}^{m}\),其\(x_{i}\)和\(x_{i}^{+}\)语义相关
采用交叉熵损失
其\(h_{i}\)和\(h_{i}^{+}\)表示\(x_{i}\)和\(x_{i}^{+}\)
对于(\(x_{i}\),\(x_{i}^{+}\))的Npair mini-batch 的训练目标为
${i}=- {{j=1}^{N} e{({i}, {j}{+}) / } } $
其中\(\tau\)为超参数,\(\operatorname{sim}\left(\mathbf{h}_{i}, \mathbf{h}_{i}^{+}\right)\)表示cos相似度\(\frac{\mathbf{h}_{1}^{\top} \mathbf{h}_{2} }{\left\|\mathbf{h}_{1}\right\| \cdot\left\|\mathbf{h}_{2}\right\|}\)
使用步骤
首先利用PLM编码输入sentence
然后利用上述对比学习目标fine-tune所有参数