TreeMix:基于组合的数据增强方法
Publish
NAACL2022
Title
TreeMix: Compositional Constituency-based Data Augmentation for Natural Language Understanding
Abstract
数据增强是解决过度拟合问题的一种有效方法。前人针对自然语言处理提出了不同的数据扩充策略,如噪声注入、单词替换、回译等。虽然有效,但它们忽略了语言的一个重要特征-组合性,复杂表达的意义是从其子部分建立起来的。受此启发,我们提出了一种用于自然语言理解的成分数据扩充方法TreeMix。具体地说,TreeMix利用选区分析树将句子分解成构成子结构,并利用Mixup数据增强技术对它们进行重组以生成新的句子。与以前的方法相比,TreeMix在生成的样本中引入了更大的多样性,并鼓励模型学习NLP数据的组合性。在文本分类和SCAN的大量实验表明,TreeMix的性能优于目前最先进的数据增强方法。
Solution problem
合成性是语言的一个关键方面,因为复句的意义是从它的子部分建立起来的。先前的工作还表明,语法树(例如,基于树的LSTM)有助于对句子结构进行建模,以便更好地进行文本分类。然而,在语言技术社区中,除了在语义分析方面的一些例外情况外,利用组合结构进行数据扩充并没有受到太多关注
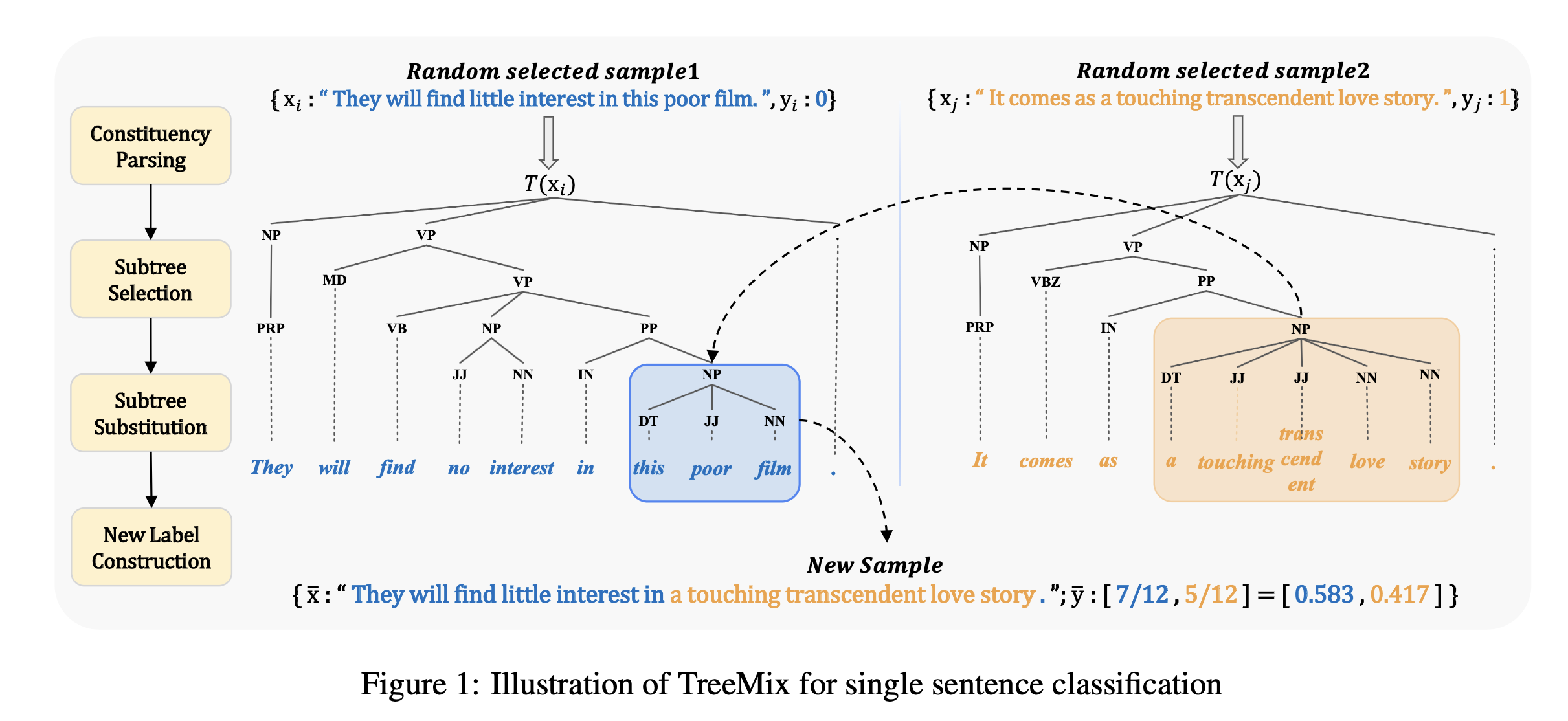
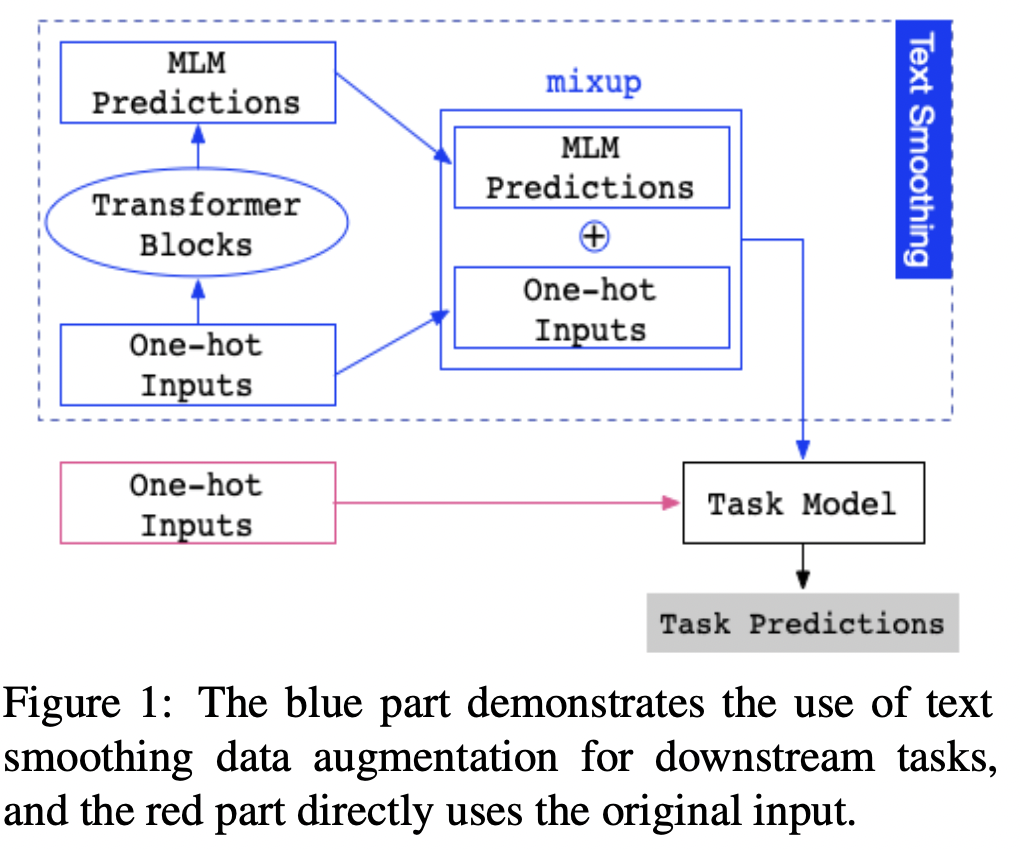
我们提出了一种用于自然语言理解的成分数据增强方法,即TreeMix(图1)。TreeMix是一种输入级混合方法,它利用成分分析信息,将来自不同句子的不同片段(子树的短语)进行重组,以创建训练集中从未见过的新示例;同时还将基于这些片段策略性地创建新的软标签。这样,TreeMix不仅利用了构成语言的特征来增加扩充的多样性,而且为这些混合的例子提供了合理的软标签。
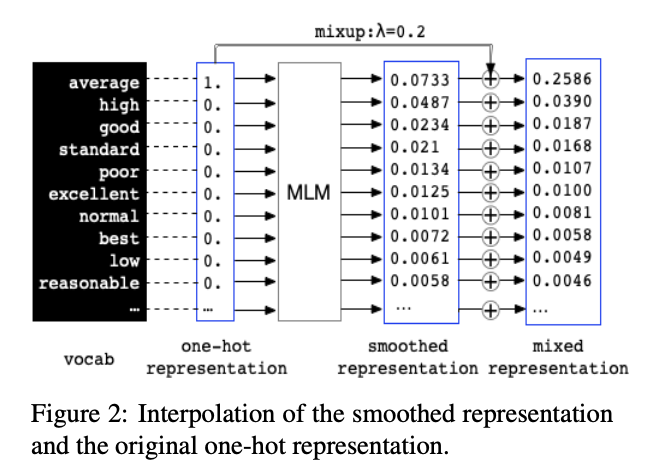
mixup定义为 \[ \tilde{x}=\lambda x_{i}+(1-\lambda) x_{j} \]
\[ \tilde{y}=\lambda y_{i}+(1-\lambda) y_{j} \]
其中\((x_i,x_j),(y_i,y_j)\)为从训练数据中随机抽出两个目标特征向量,\(\lambda\in[0,1]\)
我们通过融入语言的组合性来改进Mixup,这是泛化所必需的一个关键特征,但神经模型往往无法捕捉到这一点。我们新提出的方法TreeMix不是用整个样本进行内插,而是通过删除句子的短语并重新插入其他句子的子部分来创建新句子。TreeMix利用选民树将句子分解成有意义的组成部分,然后将这些组成部分移除并重新组合,以生成新的扩充样本。我们的目标是通过对TreeMix生成的大量样本进行训练来提高模型的组合性泛化能力。一个使用TreeMix进行单句分类的例子如上图所示。
TreeMix 详细过程
\({x}_{i}=\left\{x_{i}^{1}, x_{i}^{2}, \ldots, x_{i}^{l}\right\}\)表示长度为\(l\)的序列,其对应的one-hot编码label为\(y_i\),我们在\(x_i\)上运行一个解析器得到它的解析树\(T(x_i)\),为了获取序列中有意义的子部分,采用递归遍历解析树,获得所有具有一个以上child的子树。表示子树的集合为\(S(x_i)= \{t_i^k\}\).其中\(t_i^k\)表示样本\(x_i\)的第k个子树,对于子树\(t_i^k\)连续覆盖了\(x_i\)的\(t_{i}^{k} \triangleq\left[x_{i}^{r_{k} }, \ldots, x_{i}^{s_{k} }\right]\),索引\(r_k\)为开始,\(s_k\)为结束。例如图一左侧所示,例句子树可以cover span 的有1.this poor film,2. in this poor film, 3.no interest ...etc

对于给定的样本\((x_i,y_i)\),我们从训练集中随机抽取另一个数据点\((x_j, y_j)\)。我们对这两个句子运行选区解析器,得到它们的子树集\(S(x_i)\)和\(S(x_j)\),我们可以对要交换的子树进行采样。我们引入两个额外的超参数\(λ_L\)和\(λ_U\)来约束待采样子树的长度。\(λ_L\)和\(λ_U\),用子树与原始句子的长度之比来衡量要采样子树的上下限。直观地说,\(λ\)控制着我们想要交换的短语的粒度。我们希望交换的长度是合理的。如果它太短,那么交换不能给增强样本引入足够的多样性;否则,如果太长,这个过程可能会给原句注入太多噪音。我们设置λ为比率,以便与原句子的长度不变。表2显示了一些具有不同长度约束的子树示例。我们将长度受限子树集合定义为:
\[ S_{\lambda}(\mathbf{x}) \triangleq\left\{t \mid t \in S(\mathbf{x})\right., s.t. \left.\frac{|t|}{|\mathbf{x}|} \in\left[\lambda_{L}, \lambda_{U}\right]\right\} \] 其中\(|·|\)表示序列或子树的长度,对于两个句子\(x_i\)和\(x_j\),我们随机采样两个子树\(t_{i}^{k} \in S_{\lambda}\left(\mathbf{x}_{i}\right)\)和\(t_{j}^{l} \in S_{\lambda}\left(\mathbf{x}_{j}\right)\)并且通过\(t_j^l\)替换\(t_i^k\)构建新的样本。例如 \[ \overline{\mathbf{x}} \triangleq[x_{i}^{1}, \ldots, x_{i}^{r_{k}-1}, \underbrace{x_{j}^{r_{l}}, \ldots, x_{j}^{s_{l}}}_{t_{j}^{l}}, x_{i}^{s_{k}+1}, \ldots x_{i}^{l}] \] 其中\(t_{j}^{l}=\left[x_{j}^{r_{l} }, \ldots, x_{j}^{s_{l} }\right]\)替换\(t_{i}^{k}=\) \(\left[x_{i}^{r_{k}}, \ldots, x_{i}^{s_{k} }\right]\)如上图1所示a touching transcend love story 替换this poor film.
TreeMix制作标签
为扩充的样本\(\overline{x}\)创建有效标签是一个具有挑战性的问题。类似于Mixup,我们使用原始的凸组合两个句子的标签作为扩充样本的标签。 \[ \overline{\mathbf{y}}=\frac{l_{i}-\left|t_{i}^{k}\right|}{l_{i}-\left|t_{i}^{k}\right|+\left|t_{j}^{l}\right|} \mathbf{y}_{i}+\frac{\left|t_{j}^{l}\right|}{l_{i}-\left|t_{i}^{k}\right|+\left|t_{j}^{l}\right|} \mathbf{y}_{j} \] 其中\(l_i\)为\(x_i\)的长度,\(|t_i^k|\)为子树的长度,在新的句子中,从\(x_i\)中保留\(l_i-|t_i^k|\)个words,从句子\(x_j\)插入\(|t_j^l|\)个words。
\(\frac{l_{i}-\left|t_{i}^{k}\right|}{l_{i}-\left|t_{i}^{k}\right|+\left|t_{j}^{l}\right|}\)是来自\(x_i\)的words的分数,其可以决定\(y_i\)的权重,然后,基于标签的变化与原始句子中的长度变化成比例的猜想来创建标签。附录提供样本。

组合算法

我们的主要算法如算法1所示。虽然TreeMix创建的句子并不都是流畅的甚至有效的新句子,但它们包含具有不同含义的子部分,这鼓励模型以组合的方式构建丰富的句子表示。需要注意的是,扩展后的标签是原始标签的凸组合,只有当模型学习到两个部分的表示在一起时,它们才能预测具有不同权重的两个标签。
Training Objective
我们的模型是在原始样本和增强样本的组合上训练,以获得正则化和噪声注入之间的权衡。最终的培训目标是: \[ \begin{aligned} \mathcal{L}=& \underset{(\mathbf{x}, \mathbf{y}) \sim D}{\mathbb{E}}\left[-\mathbf{y}^{\top} \log P_{\theta}(\mathbf{y} \mid \mathbf{x})\right] +\gamma \underset{(\overline{\mathbf{x} }, \overline{\mathbf{y} }) \sim D^{\prime} }{\mathbb{E}}\left[-\overline{\mathbf{y} }^{\top} \log P_{\theta}(\overline{\mathbf{y} } \mid \overline{\mathbf{x} })\right] \end{aligned} \] \(\gamma\)i是增强样本的权重
Experiment
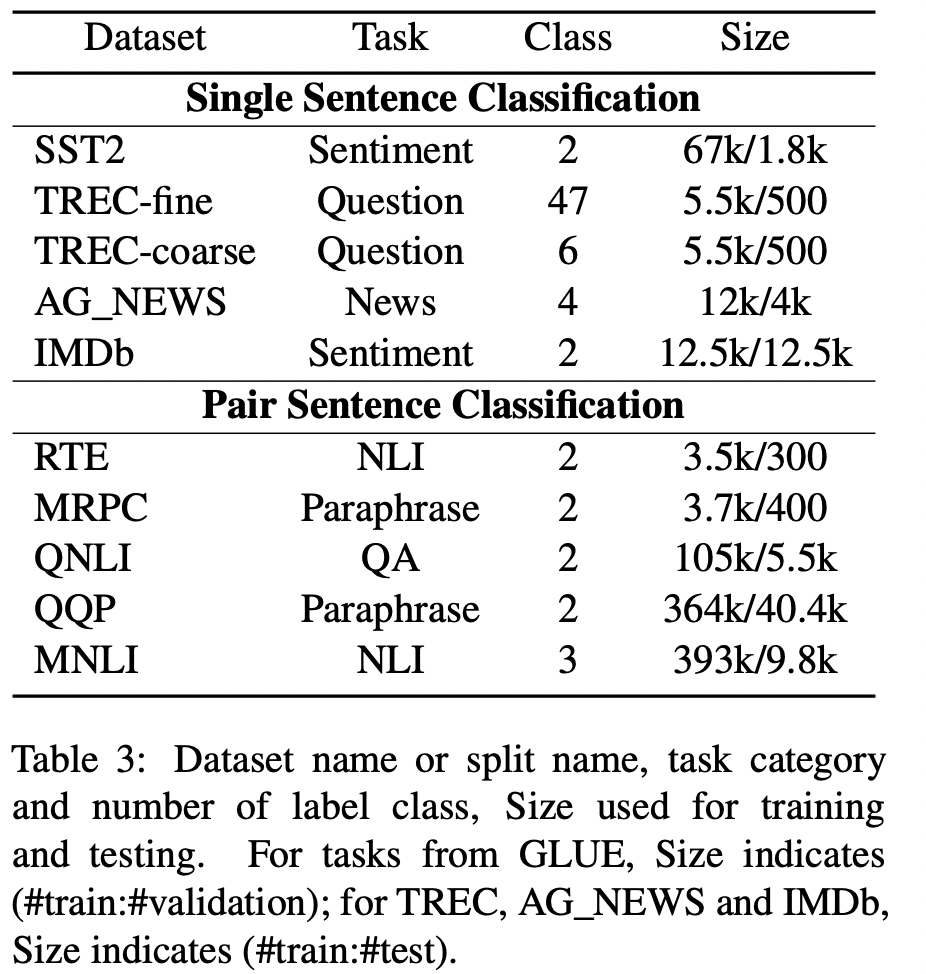
数据集
Baseline
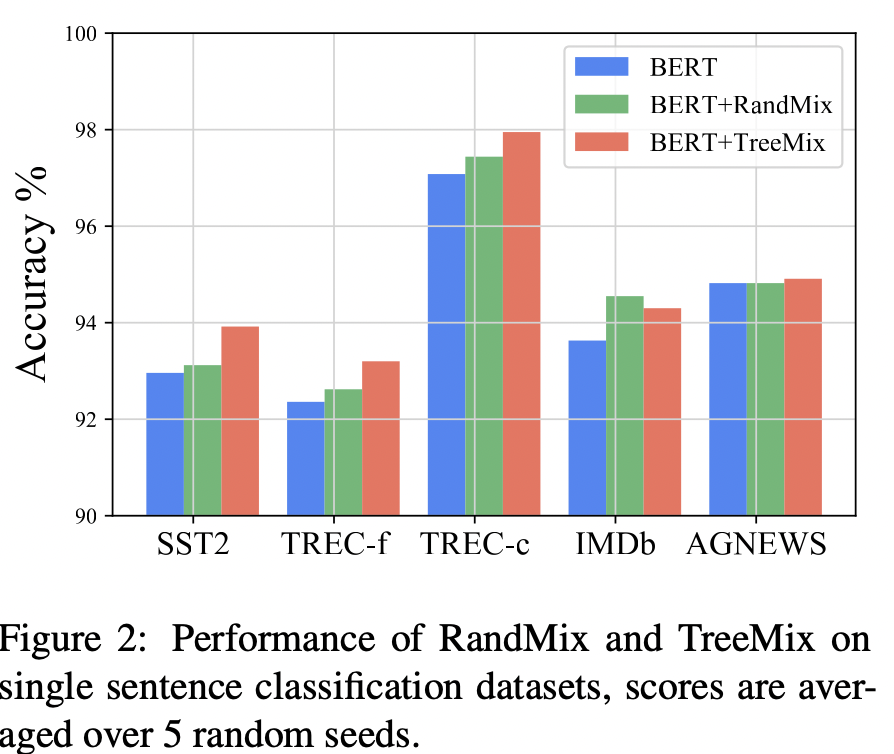
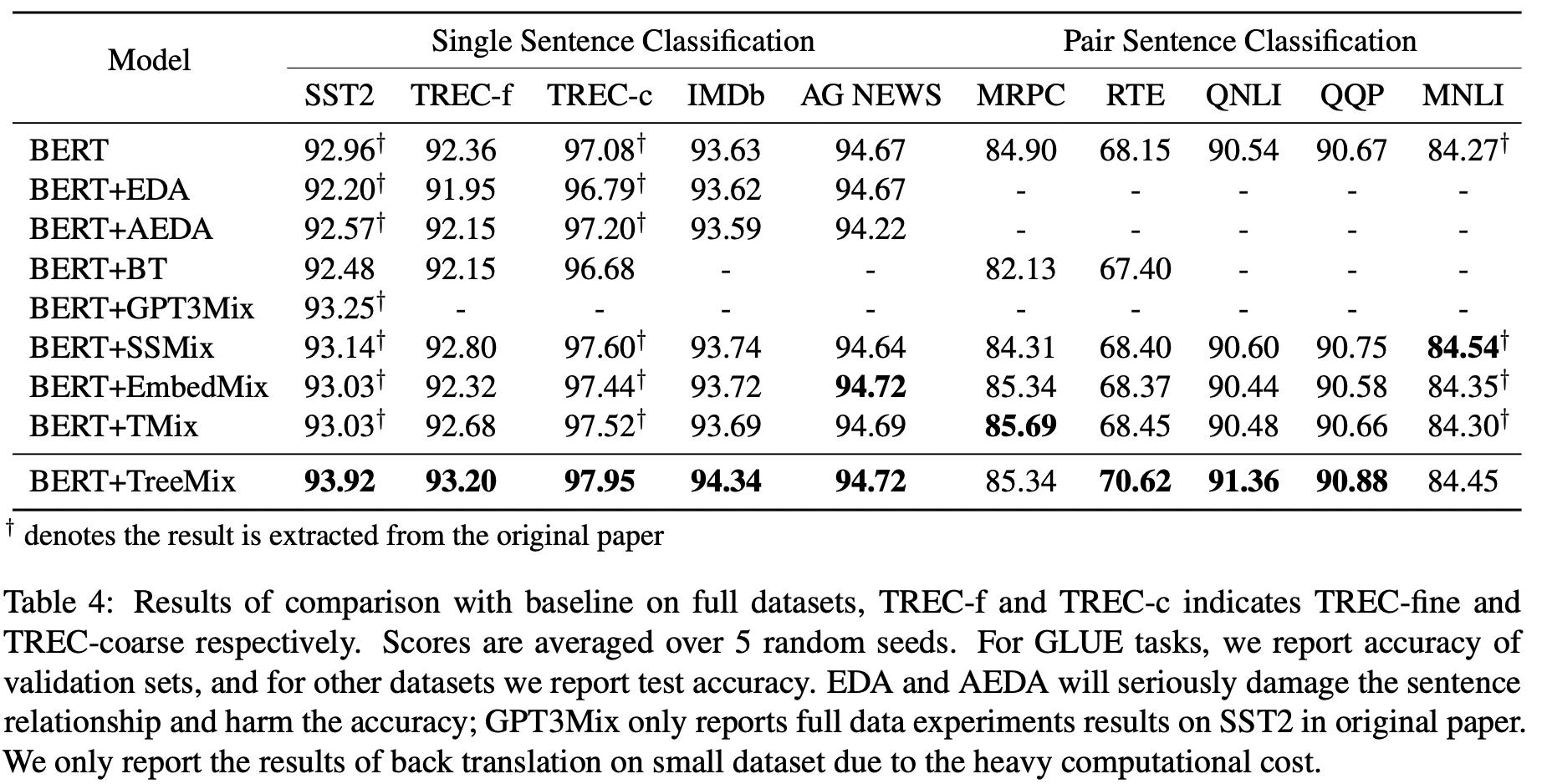
approaches 简介 BERT EDA 由四个简单操作组成:同义词替换、随机插入、随机交换和随机删除。 AEDA 在文本中随机插入标点符号的AEDA Back Translation 将句子翻译成临时语言(EN-DE),然后将先前翻译的文本翻译回源语言(DE-EN) GPT3Mix 设计提示并利用GPT3生成新的示例来训练模型。 SSMix 通过在给定类的所有示例前添加类标签来为条件BART。BARTword屏蔽了单个单词,而BARTspan屏蔽了连续的区块。 EmbedMix Tmix 首先对两个输入分别编码,然后在某一编码器层a处对两个嵌入进行线性插值,最终向前传递组合嵌入到其余层中。 结果
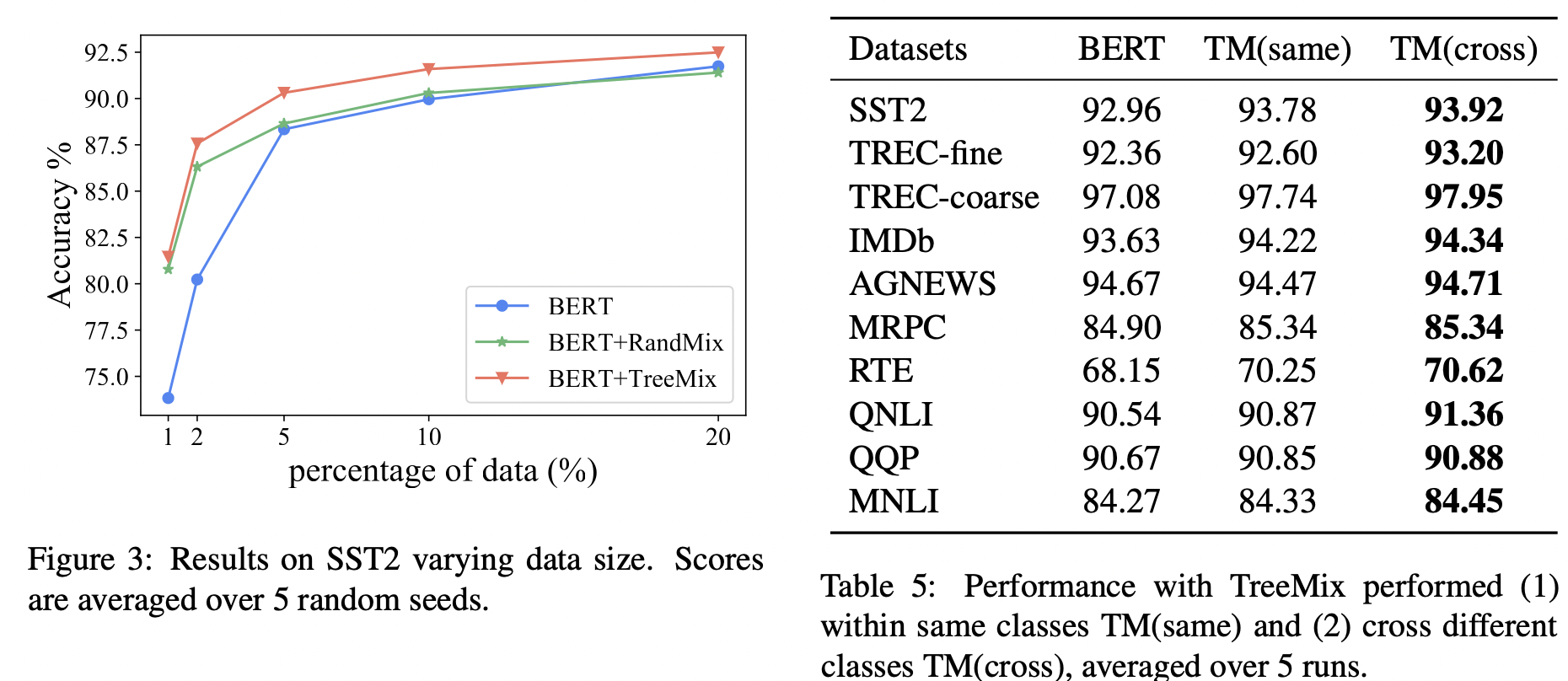
Conclusion
没找到代码,自己摸索了。