Text Smoothing:一种数据结合mix-up的数据增强方法
Publish
2022ACL
title
Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks ## solution problem 进入神经网络之前,标记通常被转换为对应的One-hot表示,这是词汇表的离散分布。平滑表示是从预先训练的MLM中获得候选token的概率,它可以被视为对onr-hot表示的更多信息的替代。我们提出了一种有效的数据增强方法,称为文本平滑,通过将句子从其one-hot表示转换为可控的平滑表示。我们在低资源条件下对不同基准的文本平滑进行了评估。实验结果表明,文本平滑方法的性能明显优于各种主流数据增强方法。此外,文本平滑可以与这些数据增强方法相结合,以获得更好的性能。
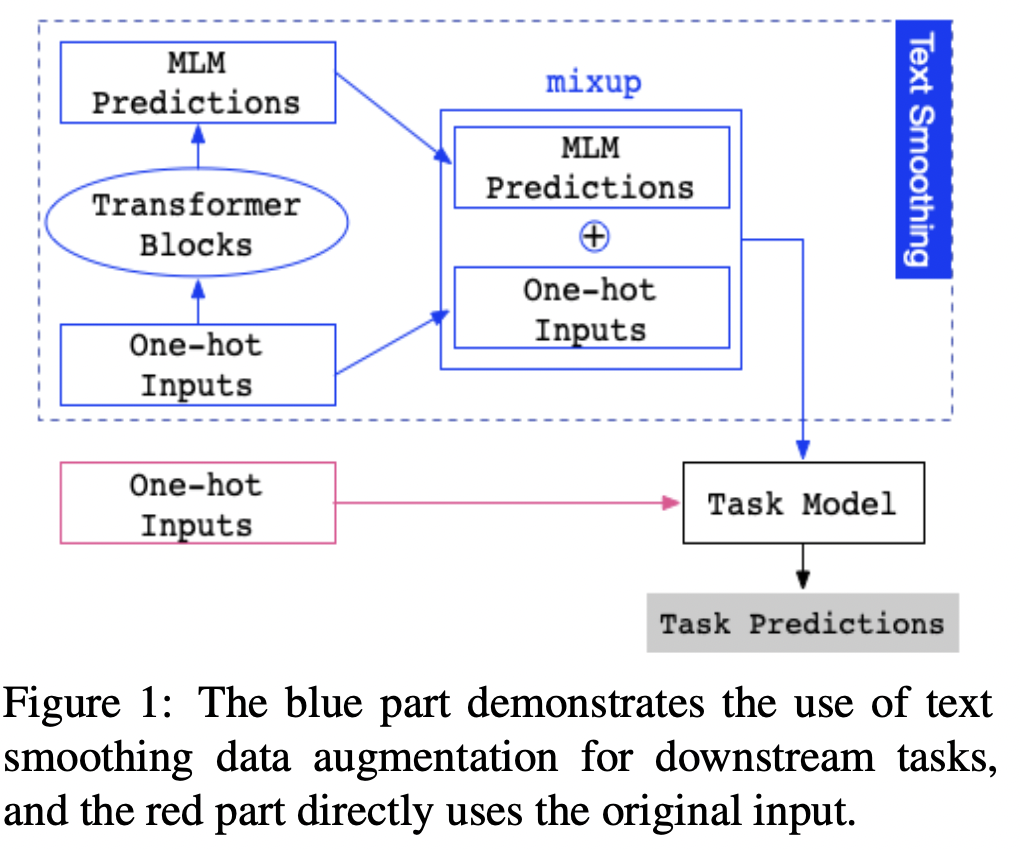
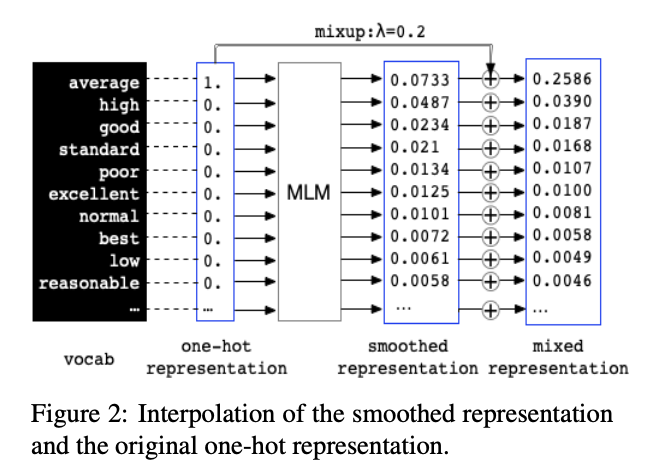
文本平滑代码:Pytorch
1 | sentence = "My favorite fruit is pear ." |
使用BERT作为MLM,给定下游数据集命名为:\(D=\{t_i,p_i,s_i,l_i\}_{i=1}^{N}\) ,N表示样本数量,\(t_i\)表示文本one-hot 编码,\(p_i\)表示\(t_i\)位置编码,\(s_i\)表示\(t_i\)的段编码,\(l_i\)表示实例标签。
将\(t_i,p_i,s_i\)送入BERT
取回BERT中Transformer-encoder最后一层的输出表示为 \[ \overrightarrow{t_i}=BERT(t_i) \] 其中\(\overrightarrow{t_i}\)形状为[seq_len,emb_size]
然后乘以\(\overrightarrow{t_i}\)乘以BERT中词嵌入矩阵\(W\),其形状为[vocab_size,embed_size] \[ MLM(t_i)=softmax(\overrightarrow(t_i)W^T) \] 其中\(MLM(t_i)\)中每一行是token词汇表中的概率分布,表示了预训练BERT学习到输入文本所在位置的包含上下文 的标记选项(信息)。
mixup定义为 \[ \tilde{x}=\lambda x_{i}+(1-\lambda) x_{j} \]
\[ \tilde{y}=\lambda y_{i}+(1-\lambda) y_{j} \]
其中\((x_i,x_j),(y_i,y_j)\)为从训练数据中随机抽出两个目标特征向量,\(\lambda\in[0,1]\)在文本平滑中,One-hot表示和平滑表示来自相同的原始输入,标签相同,其内部插入操作不会改变标签,因此mixup操作可以简化为 \[ \widetilde{t_{i}}=\lambda \cdot t_{i}+(1-\lambda) \cdot \operatorname{MLM}\left(t_{i}\right) \] 其中\(t_i\)为one-hot表示,\(MLM(t_i)\)为平滑表示,\(\widetilde{t_i}\)为联合插入表示,\(\lambda\)为用于控制插入的超参数。下游任务中我们使用联合表示代替one-hot变化表示作为输入。
Experiment
数据集
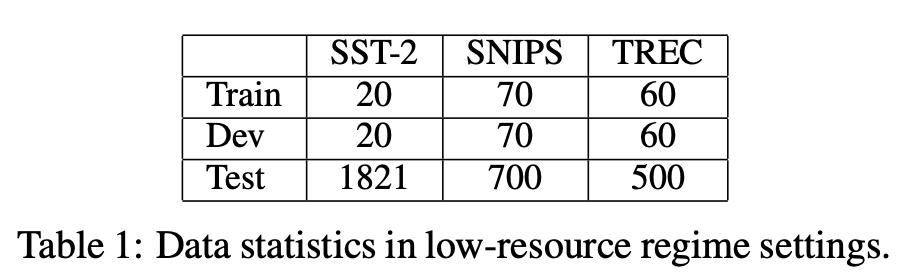
Baseline
approaches 简介 EDA 由四个简单操作组成:同义词替换、随机插入、随机交换和随机删除。 Back Translation 将句子翻译成临时语言(EN-DE),然后将先前翻译的文本翻译回源语言(DE-EN) CBERT 用预先训练的BERT mask一些标记并预测它们的上下文替换。 BERTexpand, BERTprepend 通过在给定类的所有示例中添加类标签来满足BERT条件。“expand”标签以 模拟 词汇表,而“prepend”则没有 GPT2context 为预先训练的GPT模型提供提示,并持续生成,直到[EOS]token BARTword, BARTspan 通过在给定类的所有示例前添加类标签来为条件BART。BARTword屏蔽了单个单词,而BARTspan屏蔽了连续的区块。 结果
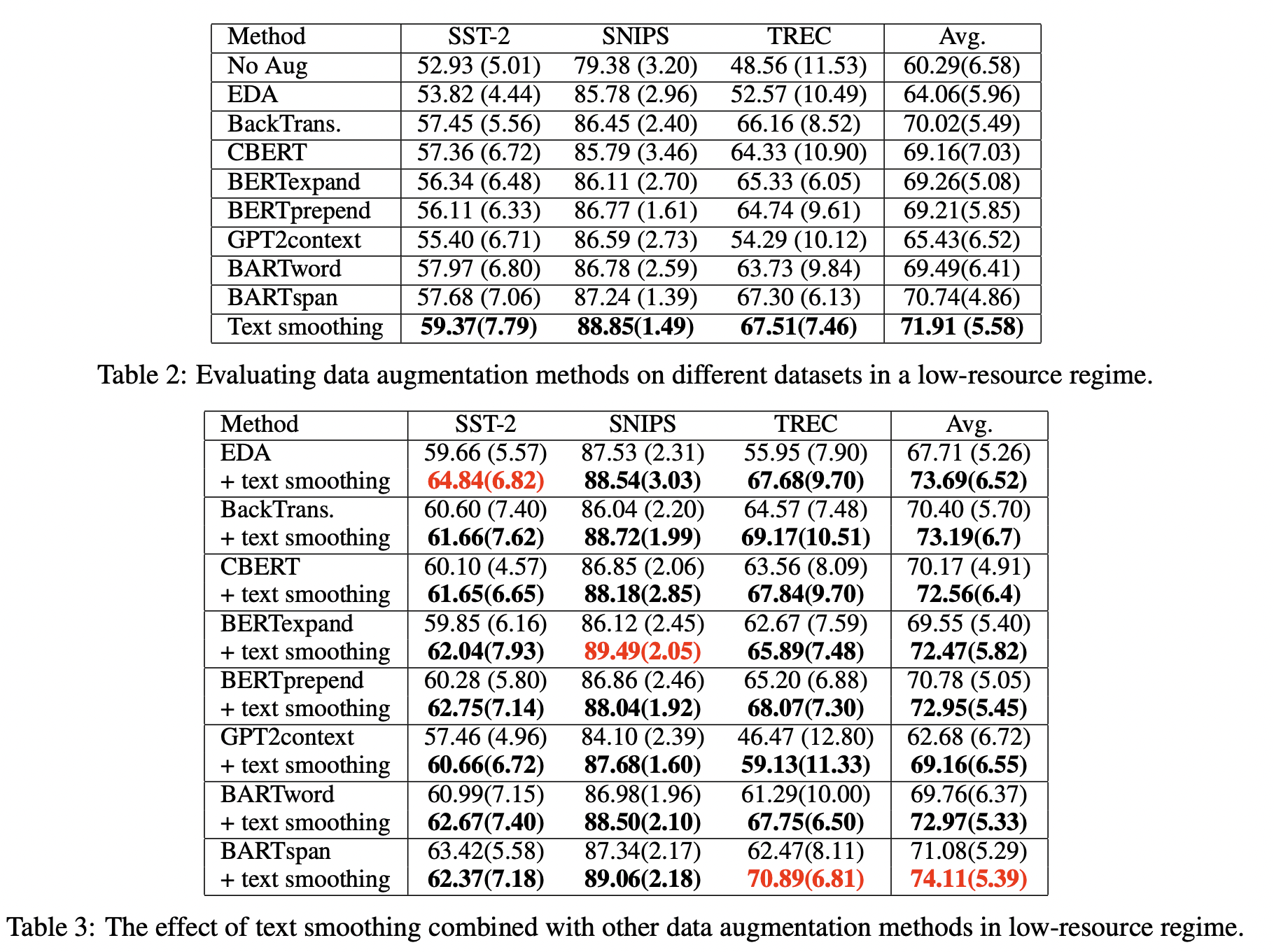
Conclusion
小数据,可控,目前优于其他,未来,结合其他DA=顶会。我也想发顶会啊。
Text Smoothing:一种数据结合mix-up的数据增强方法
install_url to use ShareThis. Please set it in _config.yml.